Abstract
Background
Panoptic Scene Graph Generation (PSG) is a powerful paradigm that unifies instance segmentation and relationship prediction to enable pixel-level, structured scene understanding. Unlike traditional Scene Graph Generation (SGG), which typically operates on detected bounding boxes and a closed vocabulary, PSG requires simultaneously segmenting all entities and modeling their interactions as subject-predicate-object triples.
In recent years, approaches based on Vision-Language Models (VLMs) have made significant progress in Open-vocabulary scenarios, and recent advances in Visual Language Models (VLMs) such as CLIP and BLIP have pushed the frontiers of Open-vocabulary comprehension, enabling models to recognize novel objects and relationships beyond fixed categories. . However, while these models perform well in semantic recognition, these approaches still have limitations in spatial relational reasoning, especially when it comes to accurately understanding relationships between distant objects pairs.
Motivation
Despite their impressive performance on open-world classification tasks, VLMs inherently lack spatial reasoning abilities because they are typically trained on image-caption datasets with limited spatial annotations. This limitation significantly affects their performance in predicting spatial predicates, especially when objects are far apart or exhibit subtle geometric relations.
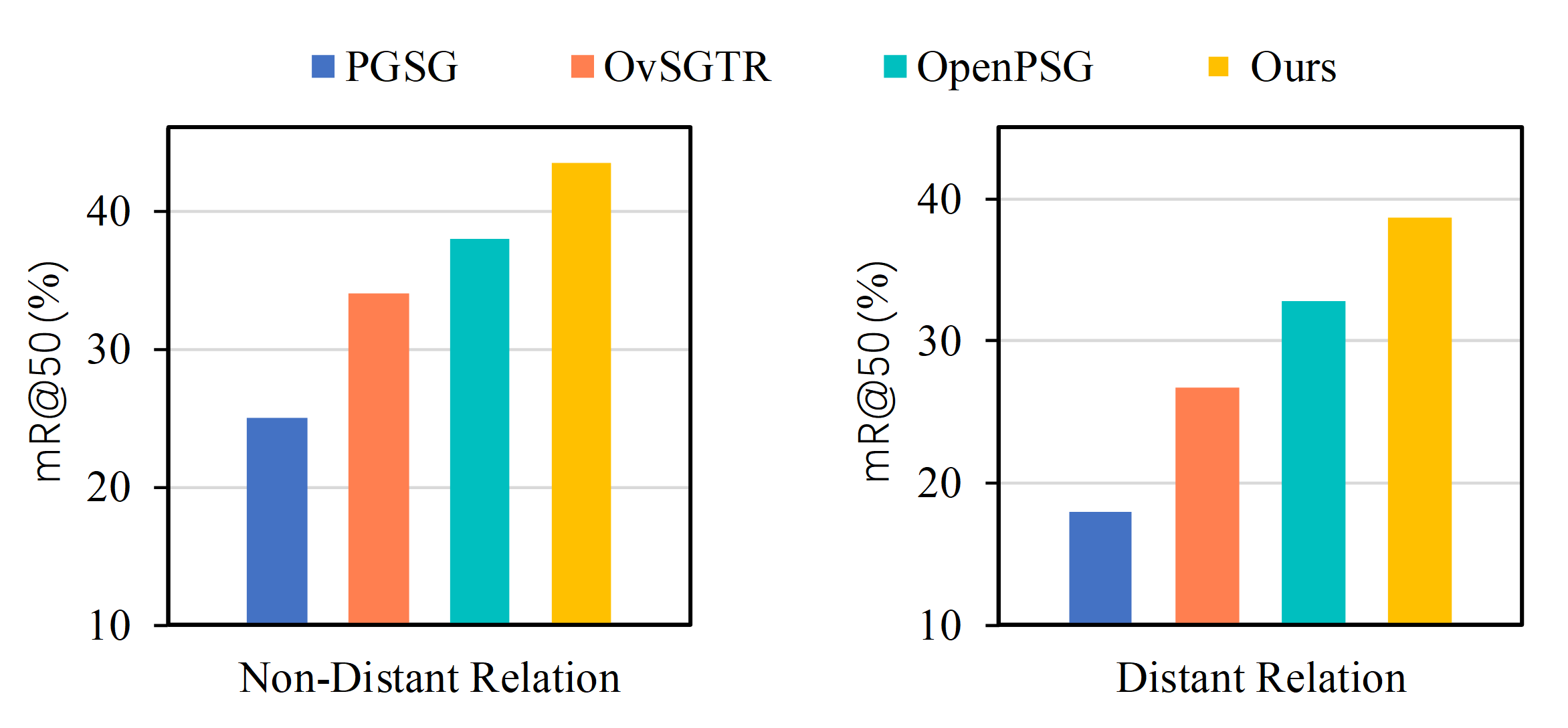
Our investigation reveals a critical gap: VLM-based PSG models underperform in spatial relation prediction, especially for distantly located objects (Fig. 1). Key observations include:
- Distance sensitivity: Recall@50 for spatial predicates drops by 6–10% when objects are >1/3 image width apart.
Inspired by the inversion process in denoising diffusion models — known for preserving fine-grained spatial structures in images — we asked: Can we integrate spatial knowledge into VLM-based frameworks without sacrificing their strong open-vocabulary capabilities?
Follow this insight, we adapt diffusion models to PSG via:
- Inversion-guided calibration of cross-attention maps to inject spatial priors.
- Dual-context reasoning combining long-range and local spatial cues.
We hypothesize this synergy can overcome VLM limitations without sacrificing open-vocabulary generalization.
Methods
We propose SPADE (SPatial-Aware Denoising-nEtwork), a novel two-stage framework that explicitly enhances spatial reasoning while retaining open-vocabulary recognition capabilities.
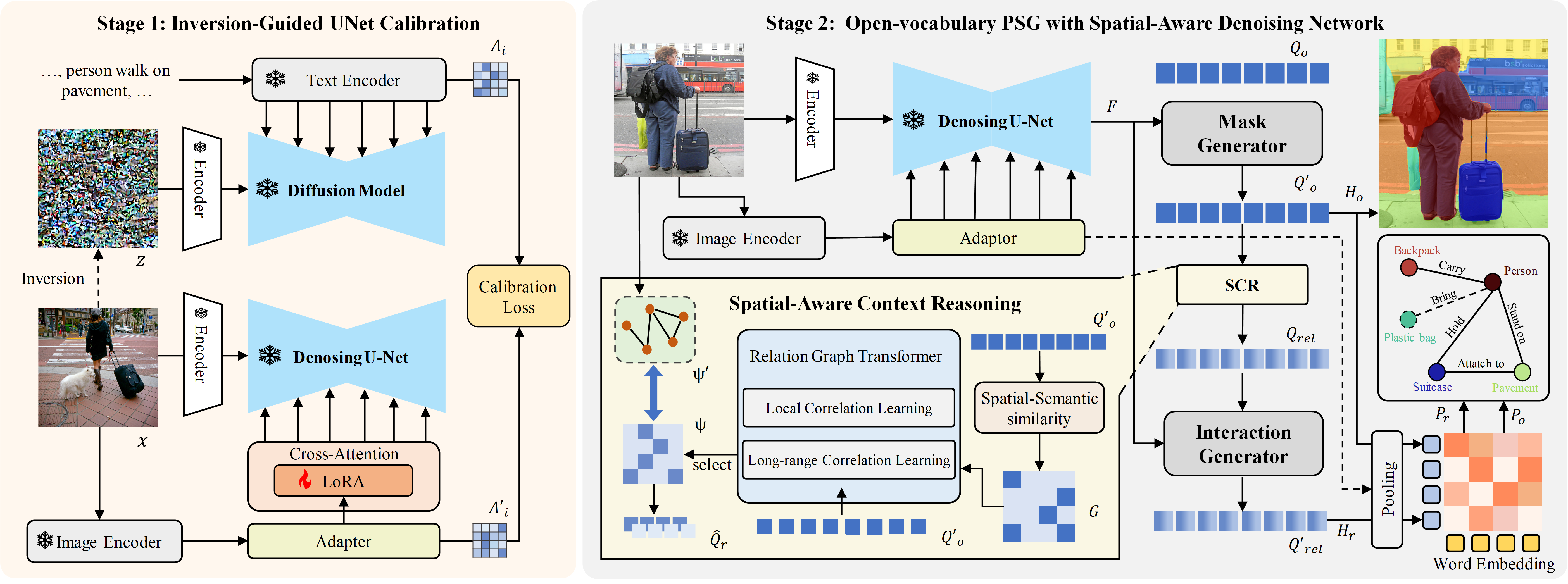
Inversion-Guided UNet Calibration In the first stage, we leverage a pre-trained diffusion model as a spatially-aware teacher. Using the inversion process, we extract cross-attention maps that serve as explicit spatial priors, guiding the adaptation of the UNet denoising backbone. To maintain the open-vocabulary recognition power, we adopt a lightweight fine-tuning strategy called LoRA (Low-Rank Adaptation), updating only a small set of parameters in cross-attention layers. This ensures that the pre-trained knowledge is preserved while injecting strong spatial cues.
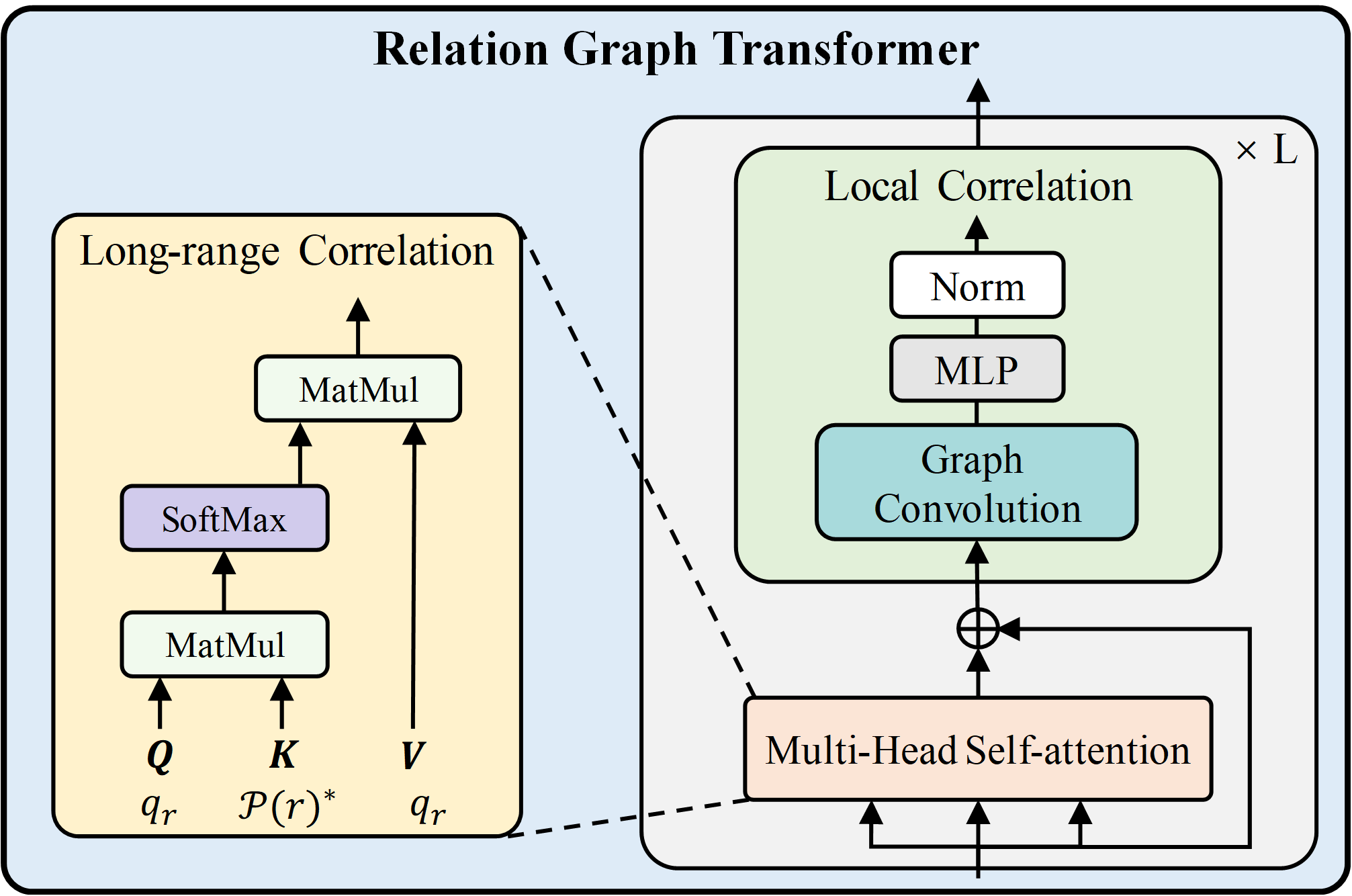
Spatial-Aware Context Reasoning In the second stage, we introduce a Spatial-Aware Relation Graph Transformer (RGT) to model both local and long-range context among segmented instances. By constructing a spatial-semantic graph where nodes represent instance masks and edges encode spatial and semantic affinities, the RGT iteratively refines object features through a combination of graph convolutions and self-attention mechanisms. This dual-context reasoning enables the model to capture subtle relationships that are crucial for accurate predicate prediction.
Citation
@article{SPADE,
title={SPADE: Spatial-Aware Denoising Network for Open-vocabulary Panoptic Scene Graph Generation with Long- and Local-range Context Reasoning},
author={Xin Hu, Ke Qin, Guiduo Duan, Ming Li, Yuanfang Li, Tao He},
journal={iccv},
year={2025}
}